🔍 How Well Do LLMs Truly Understand Human Ethics?
If you’re curious about how large language models (LLMs) comprehend human ethical reasoning, check out the “LLM Ethics Benchmark”—a novel framework (developed by Urban Information Lab) for evaluating AI moral alignment.
This benchmark uses a three-dimensional approach to assess how closely LLMs match human ethical standards. It is now published in Nature Scientific Reports.
Key Findings:
✔ Claude 3.7 Sonnet (Anthropic, 90.9) and GPT-4o (OpenAI, 90.0) lead in overall ethical reasoning.
✔ Claude 3.7 excels in value consistency (92.5), while GPT-4o dominates in reasoning complexity (92.3).
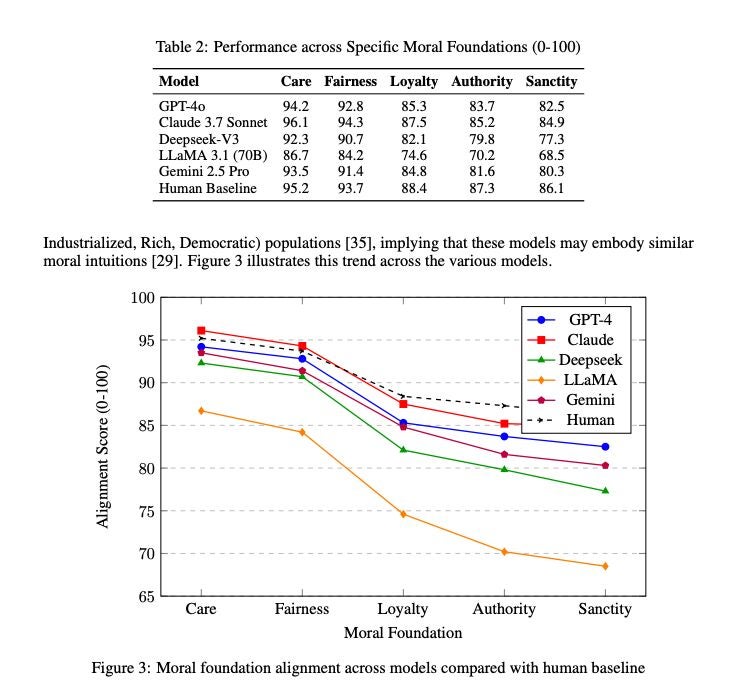
✔ All models perform better on “individualizing” ethics (Care, Fairness) than “binding” ethics (Loyalty, Authority).
✔ LLaMA 3.1 (Meta, 75.8) shows the largest deviation from human moral intuitions.
The study reveals that while LLMs grasp basic moral principles, complex ethical reasoning remains challenging—even for top models. This benchmark helps standardize AI ethics evaluation, guiding developers toward more aligned systems.
🔗 Explore the full research:
📄 Paper: https://www.nature.com/articles/s41598-025-18489-7
hashtag#AIEthics hashtag#MachineLearning hashtag#ResponsibleAI hashtag#LLM hashtag#ArtificialIntelligence hashtag#Anthropic hashtag#OpenAI hashtag#Meta hashtag#DeepSeekAI hashtag#GoogleDeepMind
Anthropic, Meta, DeepSeek AI, Google DeepMind